
티스토리 뷰
이 포스팅은 만들면서 배우는 클린 아키텍처를 읽고 작성하였습니다.
단일 책임 원칙
이 원칙의 일반적인 해석은 "하나의 컴포넌트는 오로지 한 가지 일만 해야 하고, 그것을 올바르게 수행해야 한다." 이지만 실제 의도는 "컴포넌트를 변경하는 이유은 오직 하나 뿐이어야 한다." 입니다. 책임을 하나의 일을 한다라기보다는 변경해야 할 이유로 해석해야 하는 것이죠.
아키텍처에서 이것을 어떻게 적용할 수 있을까요?
컴포넌트를 변경할 이유가 오직 하나라면 어떤 이유로 소프트웨어를 변경하더라도 이 컴포넌트에 대해 전혀 신경 쓸 필요가 없습니다. 소프트웨어가 변경되더라도 여전히 기대했던 대로 동작할 것이기 때문입니다.
구현하다보면 위 그림같이 됩니다. A는 다른 여러 컴포넌트에 의존하고있고, E는 의존하는 것이 전혀 없습니다. E를 변경할 유일한 이유는 E의 기능이 바뀌어야 할 때 뿐이지만 A의 경우 다른 컴포넌트가 바뀔 때 같이 영향을 받게 됩니다.
많은 코드들이 단일 책임 원칙을 위반하고있기 떄문에 시간이 갈수록 변경하기가 더 어려워지고 그로 인한 비용이 증가하며, 변경할 더 많은 이유가 생기게 됩니다. 변경할 이유가 많아진 이후에는 한 컴포넌트를 바꾸는 것이 다른 컴포넌트가 실패하는 원인으로 작용할 수 있습니다.
의존성 역전 원칙
계층형 아키텍처에서는 계층 간 의존방향이 항상 아래를 가리킵니다. 이 말은 곧 상위 계층들이 하위 계층들에 비해 변경할 이유가 더 많다는 것입니다. 따라서 영속성 계층에 대한 도메인 계층의 의존성 때문에 영속성 계층을 수정하게 되면 도메인 계층을 같이 수정해야 하는 경우가 많이 있습니다. 이런 의존성을 어떻게 제거할 수 있을까요?
바로 의존성 역전 원칙(Dependency Inversion Principle)을 따르면 됩니다. 의존성 역전 원칙은 코드상의 어떤 의존성이든 그 방향을 바꿀 수 있다는 것을 의미합니다. 의존성의 양쪽 코드를 모두 제어할 수 있을 때 의존성을 역전시킬 수 있습니다. 만약 라이브러리에 의존하고 있다고하면 라이브러리를 제어하는 것은 불가능하기 때문에 의존성을 역전시킬 수 없습니다.
그렇다면 어떻게 이게 가능할까요? 도메인 코드와 영속성 코드간의 의존성을 역전시키게 되면, 영속성 코드가 도메인코드에 의존하게 되는데, 이 상황에서 도메인 코드를 변경할 이유를 줄여봅시다.
일반적인 계층구조에서 도메인 계층에 서비스는 영속성 계층의 엔터티와 리파지토리와 상효작용하고 있습니다. 엔터티는 도메인 객체를 표현하고 도메인 코드는 이 엔터티들의 상태를 변경하는 일을 하기 때문에 먼저 엔터티를 도메인 계층으로 올립니다. 그렇게되면 영속성 계층의 리파지토리가 도메인 계층에 있는 엔터티에 의존하게 되기 때문에 두 계층에 순환 의존성이 생기게 됩니다.
순환 의존성은 A가 B를 의존하는데 B가 다시 A를 의존하는 것을 말합니다. 바로 이 부분이 DIP를 적용할 수 있는 부분입니다.
도메인 계층에 리파지토리에 대한 인터페이스를 만들고 실제 리파지토리는 영속성 계층에서 구현하게 하면 의존성에서 해방될 수 있습니다.
클린 아키텍처
클린 아키텍처에서는 설계가 비즈니스 규칙의 테스트를 용이하게 하고, 비즈니스 규칙은 프레임워크, 데이터베이스, UI, 그 밖의 애플리케이션이나 인터페이스로부터 독립적일 수 있어야 합니다.
이는 곧 도메인 코드가 바깥으로 향하는 어떠한 의존성도 없어야 함을 의미합니다. 대신 의존성 역전 원칙을 이용해 모든 의존성이 도메인 코드를 향하게 해야합니다.
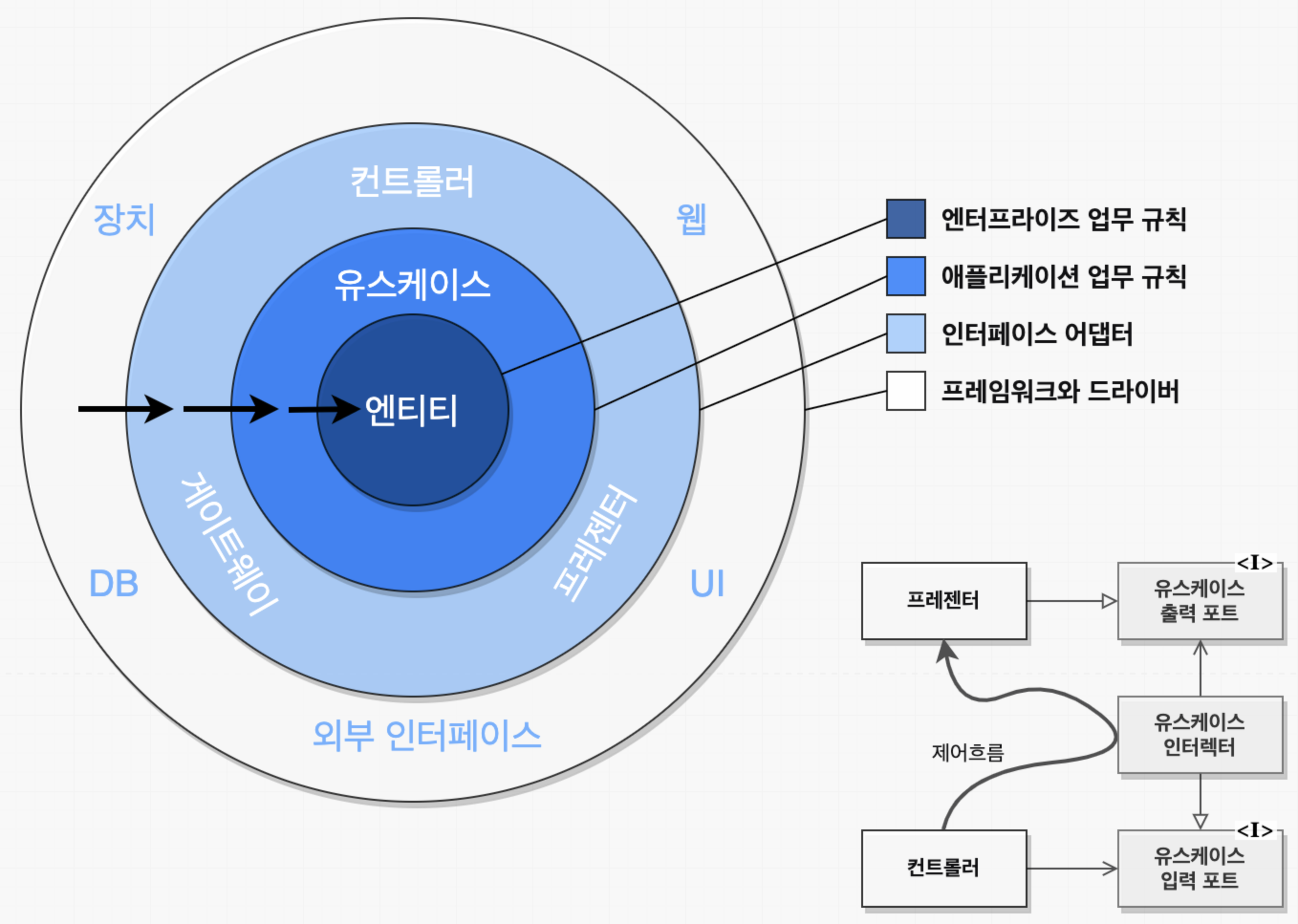
위 그림은 클린 아키텍처를 추상화 한 것으로 모든 계층이 원으로 표현되고 의존 방향은 바깥에서 안쪽으로 향하게 되어 있습니다. 이 중 코어에 해당하는 부분은 바로 유스케이스입니다. 이전까지 서비스라고 불렀던 도메인 계층의 컴포넌트인데, 단일 책임을 갖기위해 보다 세분화 되어있어 서비스가 비대해지는 것을 피할 수 있게 해줍니다. 그리고 비즈니스 규칙을 지원하는 다른 컴포넌트들이 유스케이스 주변을 감싸게 됩니다.
도메인 계층에서는 어떤 영속성 프레임워크나 UI 프레임워크가 사용되는지 알 수 없기 때문에 특정 프레임워크에 특화된 코드를 가질 수 없고 비즈니스 규칙에 집중할 수 있게 됩니다. 그래서 도메인 코드를 자유롭게 모델링 할 수 있게 되고, 도메인 주도 설계를 가장 순수한 형태로 적용해 볼 수 있습니다.
하지만 이렇게 하기 위해서는 그만한 대가가 따릅니다. 도메인 계층이 다른 계층과 철저하게 분리되어야 하므로 애플리케이션 엔터티에 대한 모델을 각 계층에서 유지보수해야 합니다. 예를 들어 영속성 계층에서 ORM 프레임워크를 사용한다고 하면 엔터티 클래스를 필요로하게 되는데, 도메인 계층은 영속성 계층을 몰라도 사용할 수 있어야하기 때문에 도메인 계층에서 사용한 엔터티 클래스를 영속성 계층에서 함께 사용할 수 없고 두 계층에서 각각 엔터티를 만들어야 합니다. 도메인 계층과 영속성 계층이 데이터를 주고 받을 때 두 엔터티를 서로 매핑해주는 과정이 필요해지는데, 이는 영속성 계층 뿐만 아니라 다른 계층과도 마찬가지 입니다.
따라서 서비스에서 사용할 모델을 정의하고 어댑터 계층에서 서비스 계층으로 넘어올 때 매핑하는 과정, 서비스 계층에서 다른 계층으로 나갈 때 해당 모델로 매핑하는 과정이 필요하게 됩니다.
이게 불필요하다고 생각하는 분들도 많을 거 같습니다. 저 또한 개발하다보면 스킵하고 진행하는 경우가 많았구요. 하지만 이렇게 함으로써 도메인 코드가 다른 계층이나 프레임워크에 의존했던 것을 해방시킬 수 있게 됩니다.
헥사고날 아키텍처
클린 아키텍처를 조금 더 발전시킨 헥사고날 아키텍처를 다이어그램으로 나타낸 그림입니다.
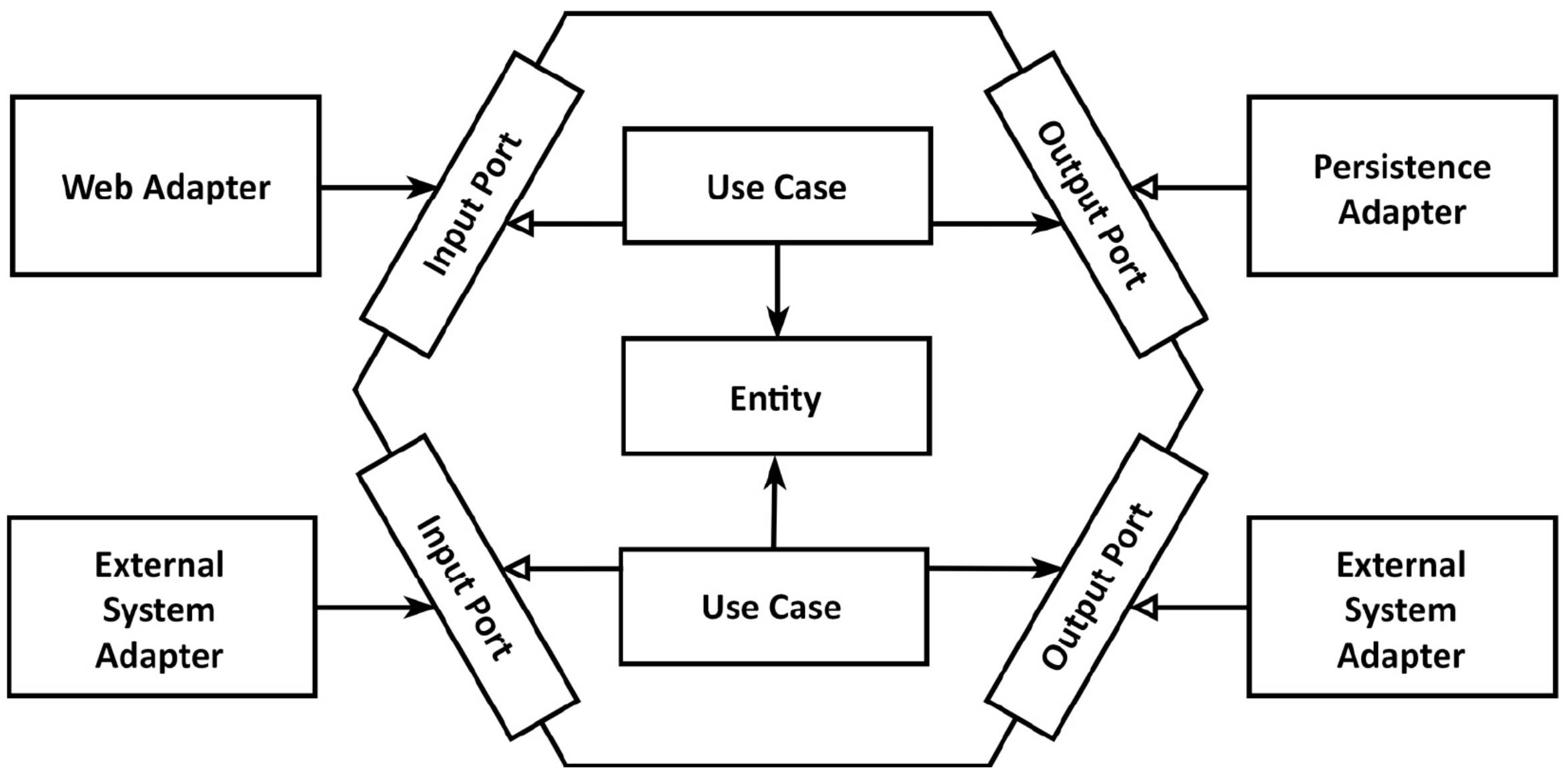
육각형 안에는 도메인 엔터티와 이와 상호작용하는 유스케이스가 있습니다. 육각형에서 외부로 향하는 의존성이 없기 때문에 클린 아키텍처에서 제시한 의존성 규칙이 그대로 적용됩니다. 반대로 모든 의존성을 코어쪽을 향하게 됩니다.
육각형 바깥에는 애플리케이션과 상호작용하는 어댑터들이 존재합니다. 어댑터는 웹, 3rd-party, 데이터베이스 등과 상호작용할 수 있습니다. 왼쪽편에 있는 어댑터들은 애플리케이션을 주도하는 어댑터이고, 오른쪽에 있는 어댑터들은 애플리케이션에 의해 주도되는 어댑터입니다.
코어와 어댑터간의 통신이 가능하려면 코어가 각각의 포트를 제공해야 합니다. 주도하는 어댑터에게는 유스케이스 클래스들에 의해 구현될 인터페이스 포트를 호출하게 되고, 주도되는 어댑터의 포트는 반대로 어댑터에 의해 구현되고 코어에 의해 호출되는 인터페이스가 됩니다. 이런 개념으로 인해 포트와 어댑터 아키텍처로 불리기도 합니다.
가장 바깥쪽 계층은 애플리케이션과 다른 시스템간의 상호작용을 담당하는 어댑터로 구성돼있고, 그 다음은 포트와 유스케이스 구현체를 결합해서 애플리케이션 계층을 구성할 수 있는데 이는 이 두 가지가 애플리케이션의 인터페이스를 정의하기 때문입니다. 마지막 계층에는 도메인 엔터티가 위치하게 됩니다.
유지보수에 도움이 되는 이유
의존성을 역전시켜 도메인 계층이 다른 계층에 의존하지 않게 함으로써 다른 계층에서의 도메인 로직 결합을 제거하면 변경할 이유를 확연하게 줄일 수 있습니다. 이런 이유가 적을 수록 유지보수성은 당연히 더 좋아지게 됩니다.
도메인 코드는 비즈니스 문제에 딱 맞게 자유롭게 모델링 할 수 있고, 영속성 코드 등 다른 계층의 코드 또한 해당 계층의 문제에 맞게 모델링 할 수 있습니다.
다음 포스팅부터 헥사고날 아키텍처를 적용해보도록 하겠습니다.
'Architecture' 카테고리의 다른 글
| 클린 아키텍처: 영속성 어댑터 구현 (0) | 2022.08.10 |
|---|---|
| 클린 아키텍처: 웹 어댑터 구현 (0) | 2022.08.08 |
| 클린 아키텍처: 유스케이스 구현 (0) | 2022.08.07 |
| 클린 아키텍처: 패키지 구성 (0) | 2022.08.03 |
| 클린 아키텍처: 계층형 아키텍처의 문제점 (0) | 2022.07.27 |
- Total
- Today
- Yesterday
- 알고리즘
- 스프링 부트 애플리케이션
- Spring Data JPA
- 함께 자라기
- proto3
- gRPC
- 클린 아키텍처
- r
- spring boot app
- Linux
- 스프링 데이터 jpa
- Jackson
- Spring Boot JPA
- 스프링 부트 회원 가입
- spring boot jwt
- 헥사고날 아키텍처
- 스프링부트
- JSON
- QueryDSL
- Spring Boot Tutorial
- JPA
- leetcode
- 스프링 부트 튜토리얼
- Java
- 스프링 부트
- spring boot application
- intellij
- @ManyToOne
- Spring Boot
- 함께 자라기 후기
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |